汉语普通话语音合成语音库
(基本库)
(1) 资源简述
此数据库为汉语普通话语音库,共包括11万字,整理为20个文本,分别为语句、数字串、生僻字、字母串、度量单位、轻声、儿话、希腊字母、疑问句、英文单词、模拟预订客房。录制产生的声音文件为44.1k采样频率、16bit量化精度的WINDOWS PCM WAV文件。共两个通道,一个通道为语音波形信号,另一个通道为声门波信号(语音基频信号)。语音库主要用于汉语普通话语音合成的测试和训练。
(2) 标注规范
n
声音文件的后期处理
u 将声音文件整理成与发音文本相匹配的单句声音文件;
u 单句声音文件的头、尾保留一定的静音段;
u 根据字典音校对声音文件。
n
文本文件的后期处理
u 录音完成后,按照要求进行文本校对;
u 按照发音人真实发音修改文本
例:‘我们’读成了‘他们’,文本修改为‘他们’
n
数据标注
u 音节标注:
l
音节在句子中的起始、中止位置(精确到1/1000秒):‘a’表示一个音节的开始,‘s’为静音段。生成的文本格式为*.sfs1。
l
标记点记录为时间点+空格+标记符号。
例:100028.sfs1
0.00000 s
0.70490 s
2.05635 s
u 韵律标注:
l
韵律分成四级,分别用#4,#3,#2,#1表示。
l
#4<1>一个完整语意的句子,切除前后可以独立成为一个句子,从听感上调形是 完全降下来的。有明显的停顿。
<2>如果是以二声词结尾的短句,这个二声的词被拖长音,且与后面是转折的关系的,有明显的停顿。也给#4。
l
#3通常标在一个韵律短语后面,有时会是一个词,从听感上调形是降下来的,但不够完全,不能独立成为一个语意完整的句子。
l
#2<1>表示被‘重读’的词或单个字(为了强调后面),有停顿,调形上有小的变化, 有‘骤停’的感觉。
(对于单音节词如果是被‘拖长音’,给#1;如果是‘骤停’要给#2)
<2>并列关系的词如果被强调重读,给#2;如果是很平滑的,给#1。
l
#1只是一种‘节奏’的边界,通常没有停顿。
l
标注后的结果,如图所示。
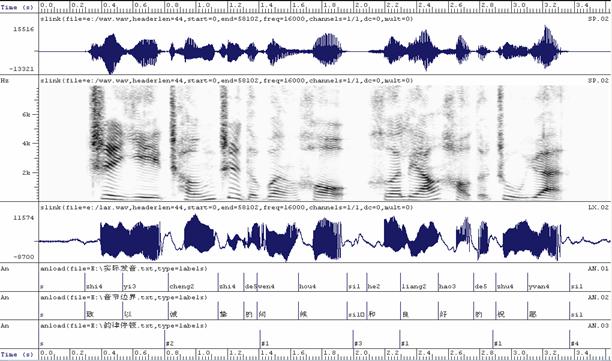
图、言语合成语音库的原始波形以及标注信息。