汉语普通话语音合成数据库
技术文档
天籁数据中心
2006年04月
1
语料库名称
2
数据库创建时间
3
产品持有者
天籁数据中心
4
目的
主要用于汉语普通话语音合成的测试和训练。
5
汉语普通话语音合成语料库的语料构成
此数据库为汉语普通话语音库,共包括11万字,整理为20个文本,分别为语句、数字串、生僻字、字母串、度量单位、轻声、儿话、希腊字母、疑问句、英文单词、模拟预订客房。
5.2
文本文件格式:
文本分为发音人文本和校对文本,两种文本格式不同,文字均以GB-2312编码进行书写。
发音人文本格式为*.doc,文本不带拼音行,句首为句子号,句子号由六位阿拉伯数字组成,后以Tab键隔开,后接文本内容,句尾以Enter键结束,文本以两栏的形式在文档中显示。
例:100001 致以诚挚的问候和良好的祝愿 100003 中国的外交工作取得了重要成果
100002 符合和平与发展的时代主题 100004 顺应世界走向多极化的趋势
校对文本格式为*.txt,一行文字,一行拼音。文字行句首为句子号,句子号由六位阿拉伯数字组成,后以Tab键隔开,后接文本内容,句尾以Enter键结束;拼音行句首为Tab键,后接文本拼音,拼音之间以空格分开句尾以空格和Enter键结束。
例:
|
文本类型 |
例 句 |
|
语句文本 |
100006 中国政府顺利恢复对香港行使主权 zhong1 guo2 zheng4 fu3 shun4 li4 hui1
fu4 dui4 xiang1 gang3 xing2 shi2 zhu3 qvan2 |
|
数字串文本 |
109500 三零一 san1 ling2 yi1 |
|
生僻字文本 |
109786 他把竹竿拗断了。 ta1 ba3 zhu2 gan1 ao3 duan4 le5 |
|
字母串文本 |
110050 EXG |
|
度量单位文本 |
111250 二十四海里 er4 shi2 si4 hai2 li3 |
|
轻声文本 |
112071 我发结巴这个词 wo3 fa1 jie1 ba5 zhe4 ge5 ci2 |
|
儿话文本 |
112451 我发老这个词 wo3 fa1
laor3 zhei4 ge5 ci2 |
|
希腊字母文本 |
112754 ξ |
|
疑问句文本 |
112775 赵庆要去售票处吗? zhao4
qing4 yao4 qv4 shou4 piao4 chu4 ma5 |
|
模拟预订客房文本 |
113134 是标准间吗?小姐。 shi4
biao1 zhun3 jian1 ma5 xiao2 jie3 |
|
英文单词文本 |
113768 Application |
6
语料库的制作技术参数
为44.1k采样频率、16bit量化精度的WINDOWS PCM WAV文件。共两个通道,一个通道为原始语音波形信号,另一个通道为声门波信号(语音基频信号)。
>45dB。
6.3
容量:
两个通道共5,809,999,736 Byte (未经压缩的语音信号)。
n
将声音文件整理成与发音文本相匹配的单句声音文件;
n
单句声音文件的头、尾保留一定的静音段;
n
根据字典音校对声音文件。
n
录音完成后,按照要求进行文本校对;
n
按照发音人真实发音修改文本。
例:‘我们’读成了‘他们’,文本修改为‘他们’。
n
制订标注规则进行标注。
n
利用计算机辅助,手工完成标注过程。
n
灵活改、编写各种辅助程序,提高加工速度。
n
经过后期校对的语料音节。
n
音节在句子中的起始、中止位置(精确到1/1000秒):
a ――音节,s――静音。
n
韵律级别:
韵律分成四级,分别用#4,#3,#2,#1表示。
n
标注准则:
n
#4<1>一个完整语意的句子,切除前后可以独立成为一个句子,从听感上调形是
完全降下来的。有明显的停顿。
<2>如果是以二声词结尾的短句,这个二声的词被拖长音,且与后面是转折的关系的,有明显的停顿。也给#4。
n
#3通常标在一个韵律短语后面,有时会是一个词,从听感上调形是降下来的,但不够完全,不能独立成为一个语意完整的句子。
n
#2<1>表示被‘重读’的词或单个字(为了强调后面),有停顿,调形上有小的变化,
有‘骤停’的感觉。
(对于单音节词如果是被‘拖长音’,给#1;如果是‘骤停’要给#2)
<2>并列关系的词如果被强调重读,给#2;如果是很平滑的,给#1。
n
#1只是一种‘节奏’的边界,通常没有停顿。
n
标注后的结果,如图2所示。
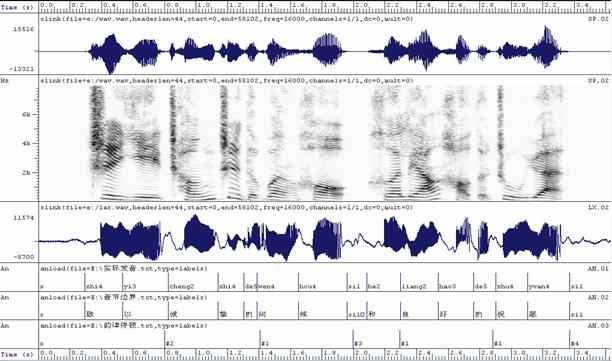
图1、言语合成语料库的原始波形以及标注信息。
7
产品光盘说明:
n
经校正并标注后的发音人文本文件及声音文件;
n
此数据库包括11万字,分为20个文本,分别为语句、数字串、生僻字、字母串、度量单位、轻声、儿话、希腊字母、疑问句、英文单词、模拟预订客房,所有文本均进行了音节和韵律的标注。
n
单通道共12679个WAV(Windows PCM)文件,双通道为25358个WAV文件。
n
MatadataTable:存放该产品的相关信息。包括:发音文本及发音人信息等内容。
n
Fundamental
Lib:存放该产品的所有声音文件。
7.3
产品容量:
该产品总容量为